Get A Massive Edge And Make Your Next T-Shirt Campaign A Winner With This Push-Button Software

SPY ON WINNING T-SHIRT CAMPAIGNS
So You Can Copy And Paste
YOUR WAY TO EASY PROFITS…
- Stop wasting time hoping your T-shirt ideas will sell
- Cloud-based software, so there’s nothing to install or updated… ever
- Uses ‘Smart Spying Technology’ to spy on WINNING T-shirt campaigns that are proven to make money
- Search active and past campaigns on all of the top T-shirt platforms for tons of great ideas (Teespring, Teechip, Viralsytle, and more!)
- Spy on actual Facebook ad campaigns for easy winners that will line your pockets with easy money
- Built-in brainstorming tools designed to give you even more t-shirt ideas and help you crush it on your ad campaigns
- Regular updates make makes this the ultimate t-shirt spying tool available
If You Nail These 3 Things, You’ll Absolutely
CRUSH IT ON YOUR NEXT T-SHIRT CAMPAIGN

Great T-Shirt Idea That People Will LOVE

Stunning Design That Stands Out

Facebook Ads That Convert Into Sales
All It Takes Is One Successful T-Shirt Campaign
TO PUT THOUSANDS OF DOLLARS IN YOUR POCKET
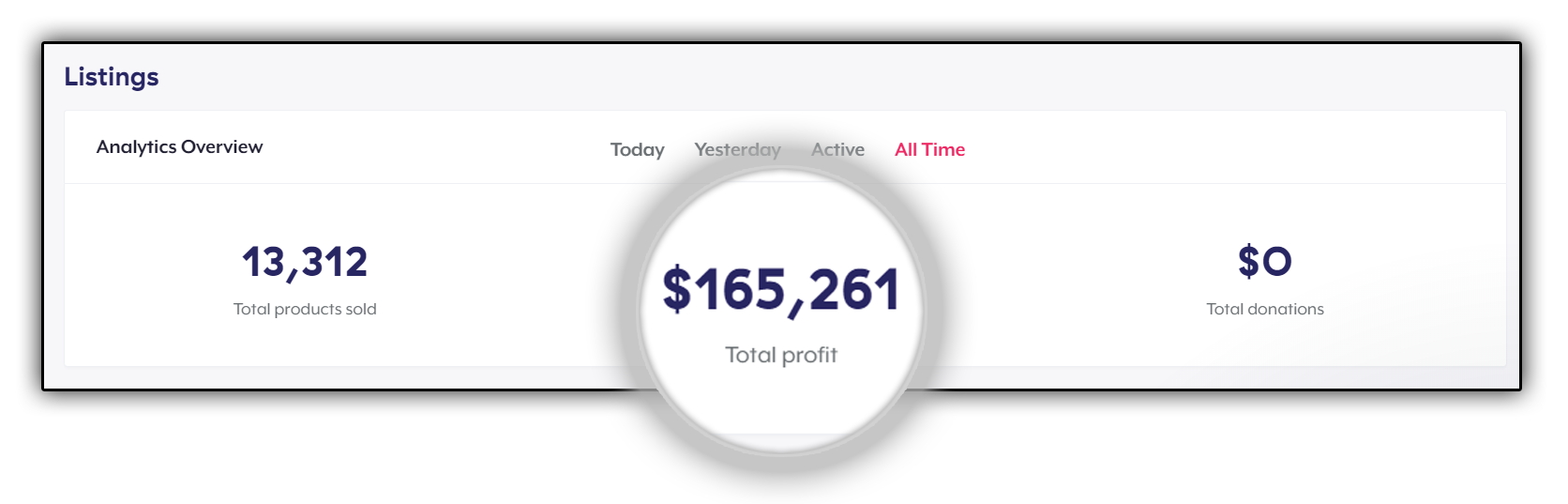
Unfortunately, Most People Struggle To Ever Make Any
SOLID MONEY FROM THEIR T-SHIRT CAMPAIGNS

- You MUST have a good design
- You need a super targeted idea
- And you need to have a solid Facebook ad campaign…
It’s not as easy as it looks.
And if you’re missing any of those 3 things, you will FAIL.
Period.
The days of just throwing up a random campaign, sending ads, and making money are GONE.
Or you will struggle a lot to turn a solid profit.
Sadly, Most Campaigns Fail
BEFORE A SINGLE AD EVER GOES LIVE
That’s because…
...the idea for the T-shirt design is boring, not well thought out, or doesn’t have an attractive and appealing design.
So what’s the answer?
If you want to bank money like this on your next T-shirt campaign…
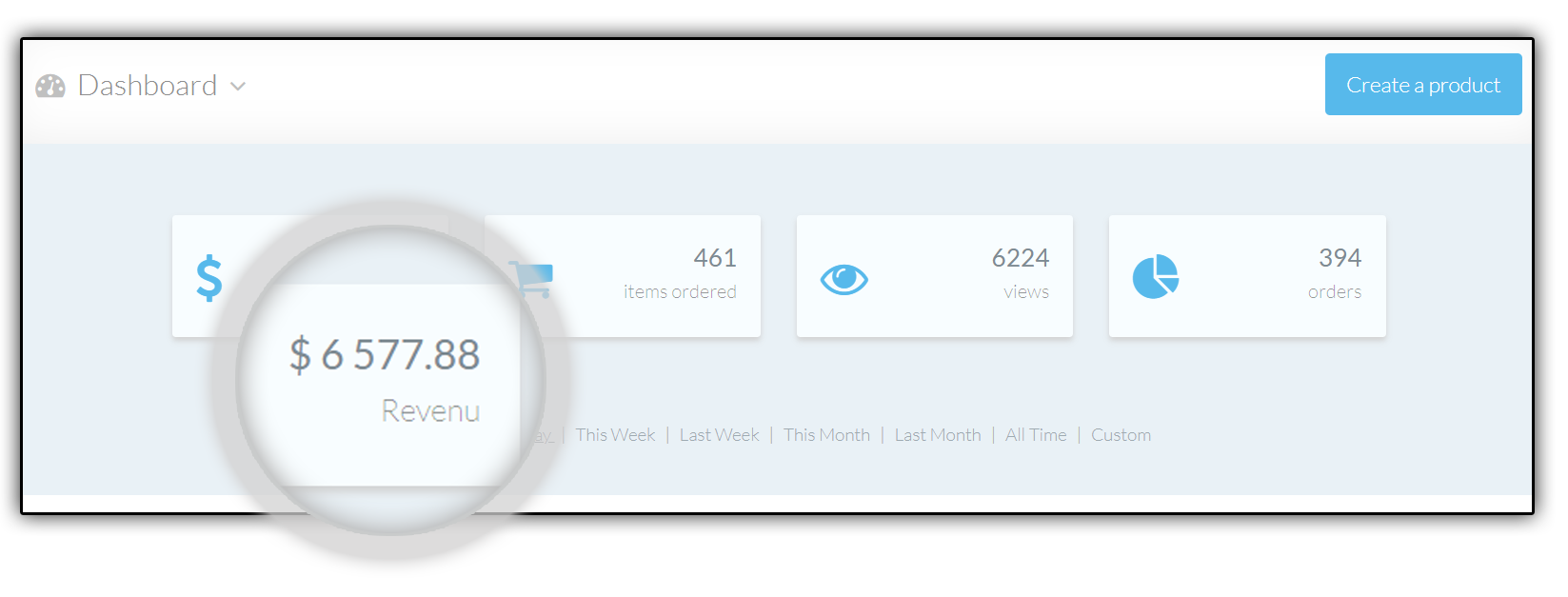
...You Need To Stop Trying
TO REINVENT THE THE WHEEL!

And You Need To Do
WHAT’S ALREADY PROVEN TO WORK.
In short, You need to spy on winning campaigns and copy what they’re doing to profit.
Yes, it’s a little sneaky.
But it’s perfectly legal.
And it’s a great way to skip all the headaches and start cranking out winning campaign after winning campaign…
Just Like This…

There Is One Problem With
SPYING THE ‘OLD FASHIONED’ WAY…

If you’re trying to spy on campaigns all on your own, it has its own set of challenges...
- It can take a lot of time to find winning campaigns to spy on.
- Sometimes it’s hard to get access to all of the underlying data you need to make sure a campaign is really a solid winner
- And once you get a good idea, you still need to come up with some solid ad campaigns to get traffic to your new T-shirt campaign
The good news is…
We’ve created a simple, automated software tool that makes it easy to SPY on winning campaigns AND the exact ads being used to shortcut your way to T-shirt selling success...
Introducing…

Teespy
Teespy is an easy-to-use, cloud-based app that lets you spy on winning t-shirt campaigns and the exact Facebook ads being used so you can save time, avoid frustration, and make big money on your next campaign.
Watch Teespy In Action
And See Just How Easy It Is To Make
$10,000+ ON A SINGLE CAMPAIGN
Spy On T-Shirt Campaigns
ON THE FOLLOWING PLATFORMS


Teechip
And more...
3 Simple Steps To Profit Like Crazy On Your
NEXT T-SHIRT CAMPAIGN WITH TEESPY
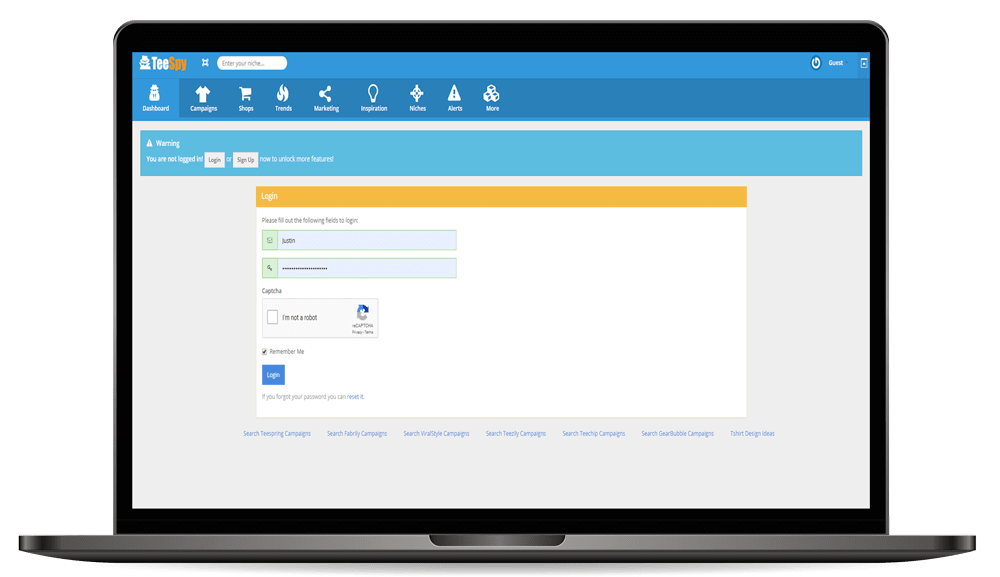
STEP 1
Login to Teespy (It’s cloud-based so you can use it from any device with an internet connection)
STEP 2
Enter a keyword to start spying
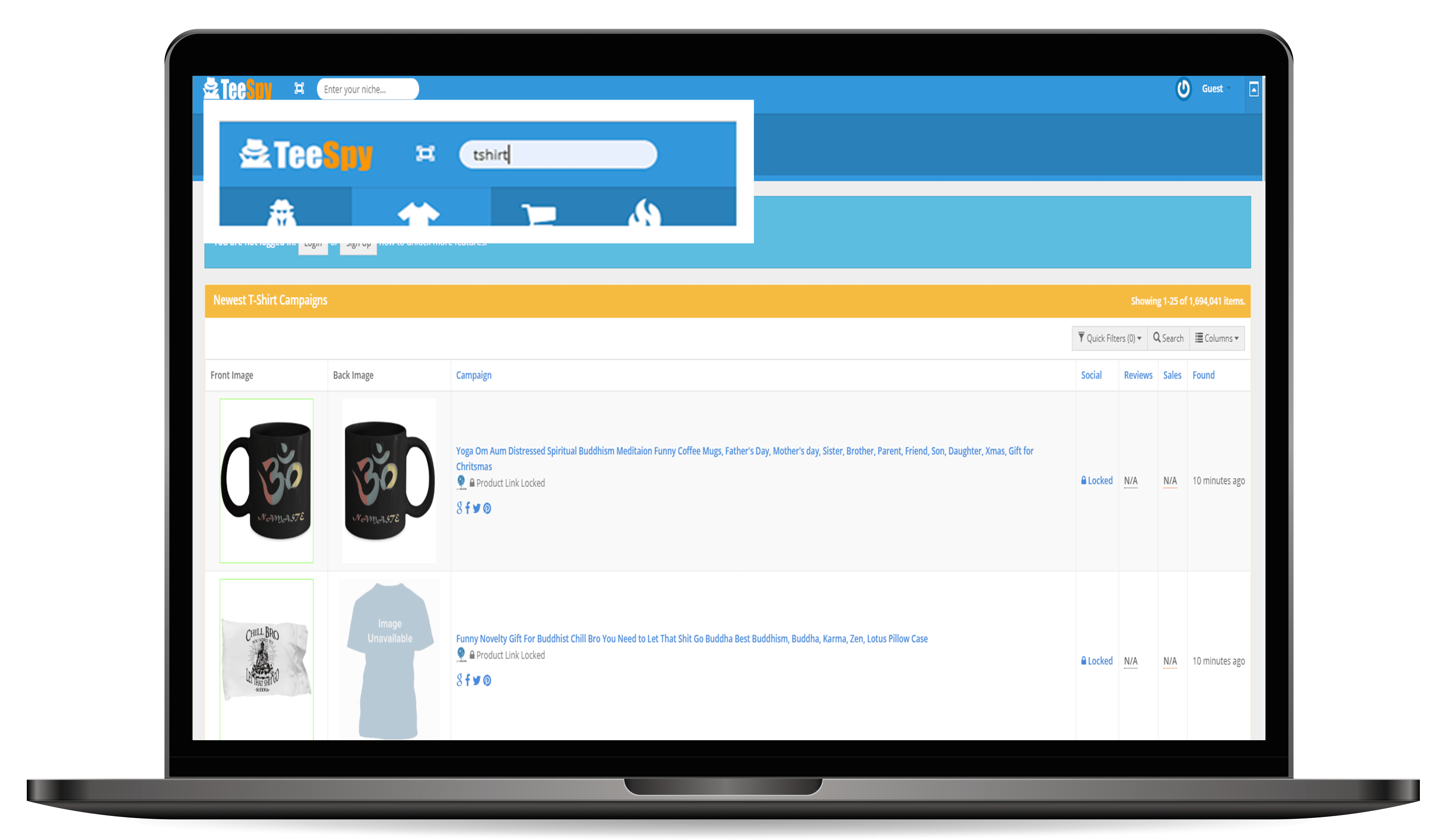
STEP 3
Get access to all kinds of t-shirt ideas, spy on winning campaigns, and get access to real Facebook ad campaigns so your next t-shirt campaign will be a MASSIVE success!
Teespy Is Loaded With Features That Make It Easy
TO PROFIT BIG ON YOUR NEXT CAMPAIGN

Get Inspired!
With TeeSpy you have the opportunity to find and analyze top performing custom apparel campaigns. This includes Teespring campaigns and many more!
Facebook Ad Spy Tool
See the promotional efforts of your competitors. Our FB ad spy tool allows you to see the LIVE ADS being ran by your competitors.


Powerful Inspiration Tools
The Inspiration Tool inside of TeeSpy allows you to search for the most popular posts on Pinterest, Wanelo, Skreened, Zazzle, and Cafe Press.
Data at Your Fingertips
TeeSpy offers a robust set of data for every t-shirt campaign including sales QTY, social shares, and even demographics!


Easy Targeting For Winning Campaigns
Unlike the other tools out there, our FB interest tool returns only VALID Facebook interests. Perfect for marketing your Teespring campaigns!
Top Notch Support
Unlike our competitors we're here for you… and always will be! Support requests are usually handled within 24 hours.

DO YOU REALLY NEED TEESPY?

Maybe you’ve had a winning campaign in the past and think you don’t need this…
...or that Teespy does something that you could do on your.
It’s true, you can find winning campaigns on your own.
But it takes a TON of time and effort.
Imagine clicking your mouse and having access to everything you need to crank out a big winner that will bank you thousands of dollars right at your fingertips…
Within SECONDS of starting your search, you’ll be able to get access to multiple t-shirt ideas and actual ad campaigns so you can ‘copy and paste’ your way to the big money.
Because Teespy searches across Facebook and ALL of the major t-shirt platforms, you’ll save countless hours when compared with doing it all on your own.
And most importantly…
YOU’LL FOREVER PUT AN END TO SEEING THIS…

AND START SEEING MORE OF THIS…
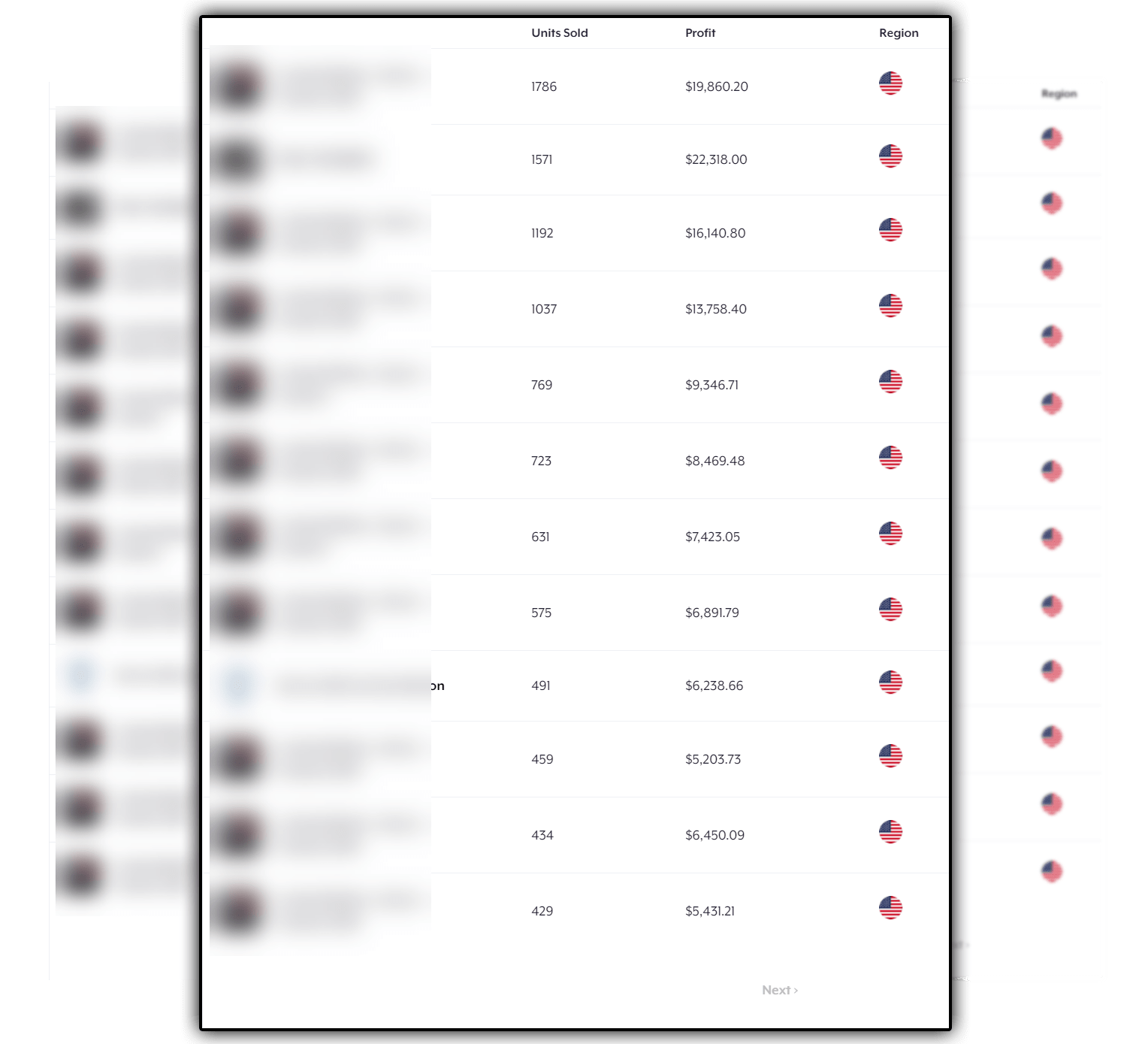
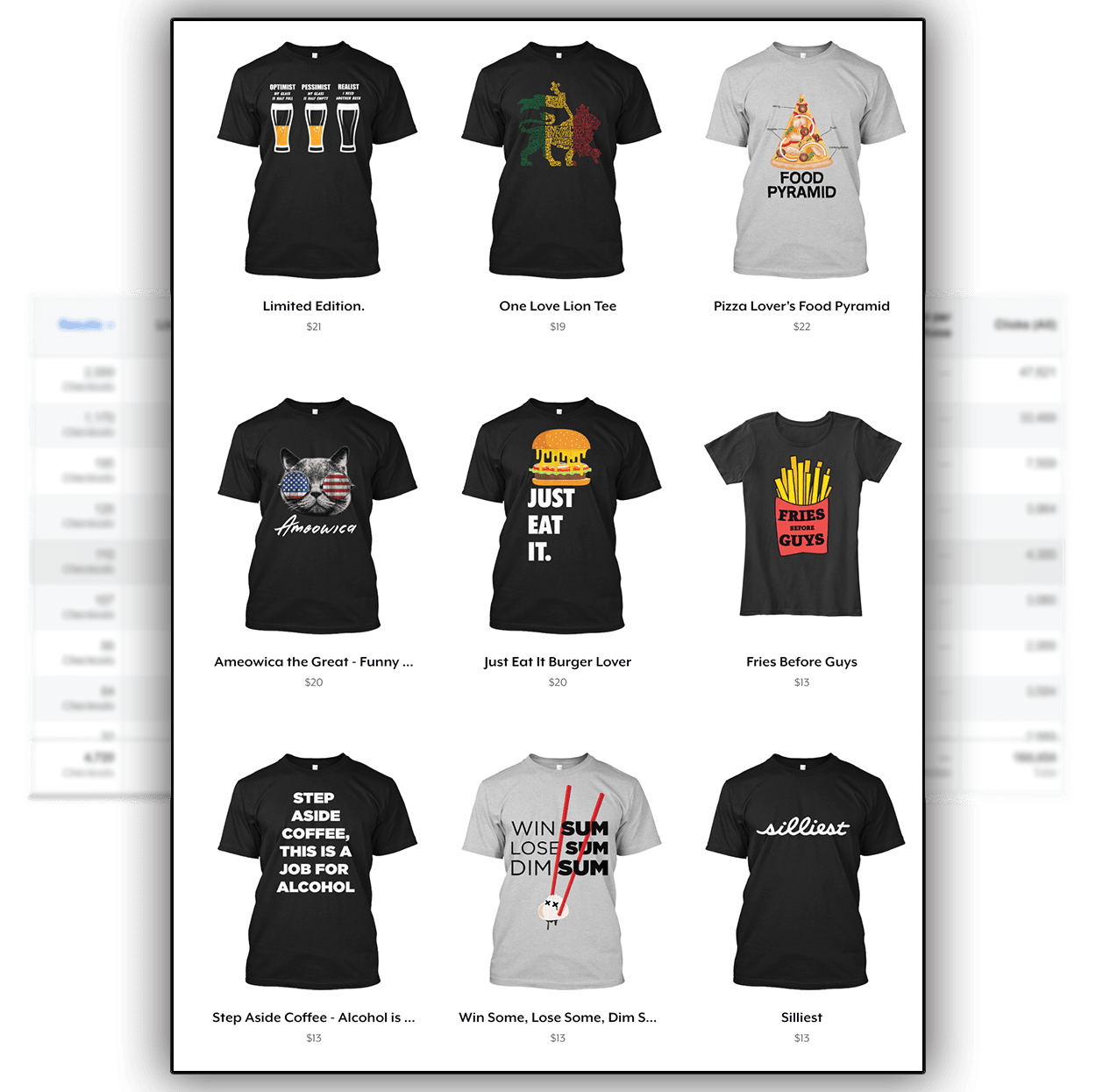
Start Spying On Winning Campaign In Just Seconds…
Get All The Data You Need To Make Your Next Campaign Super Profitable
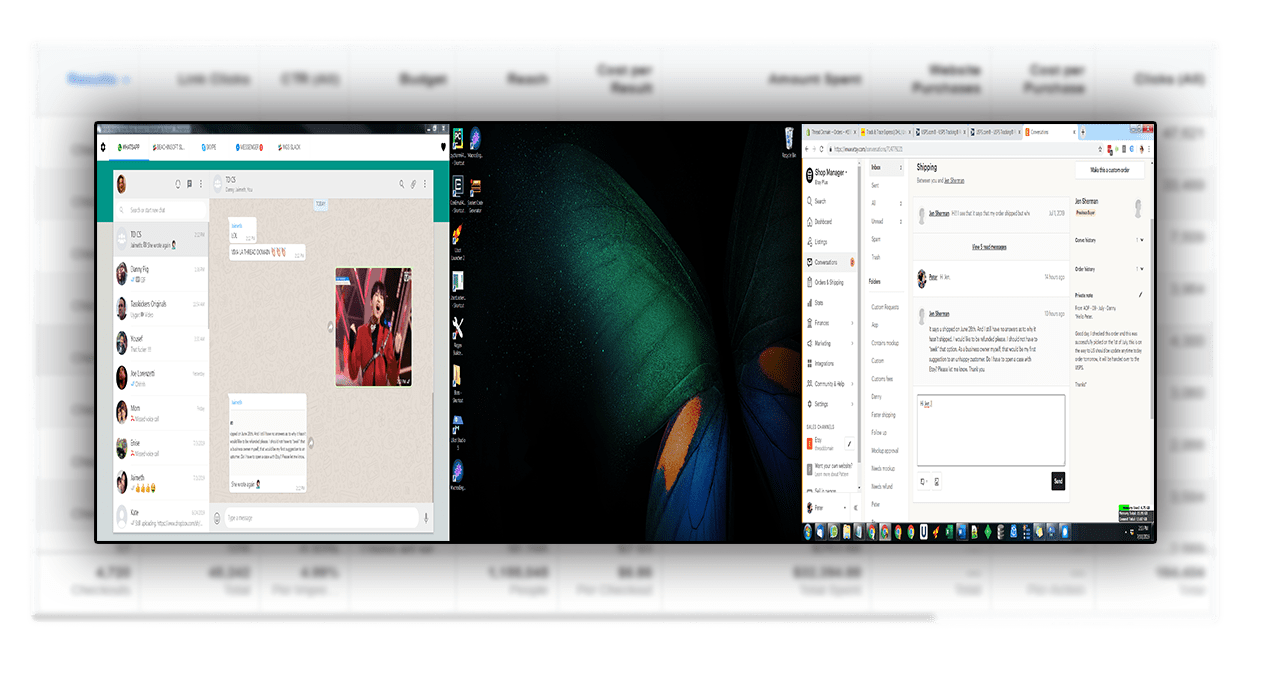
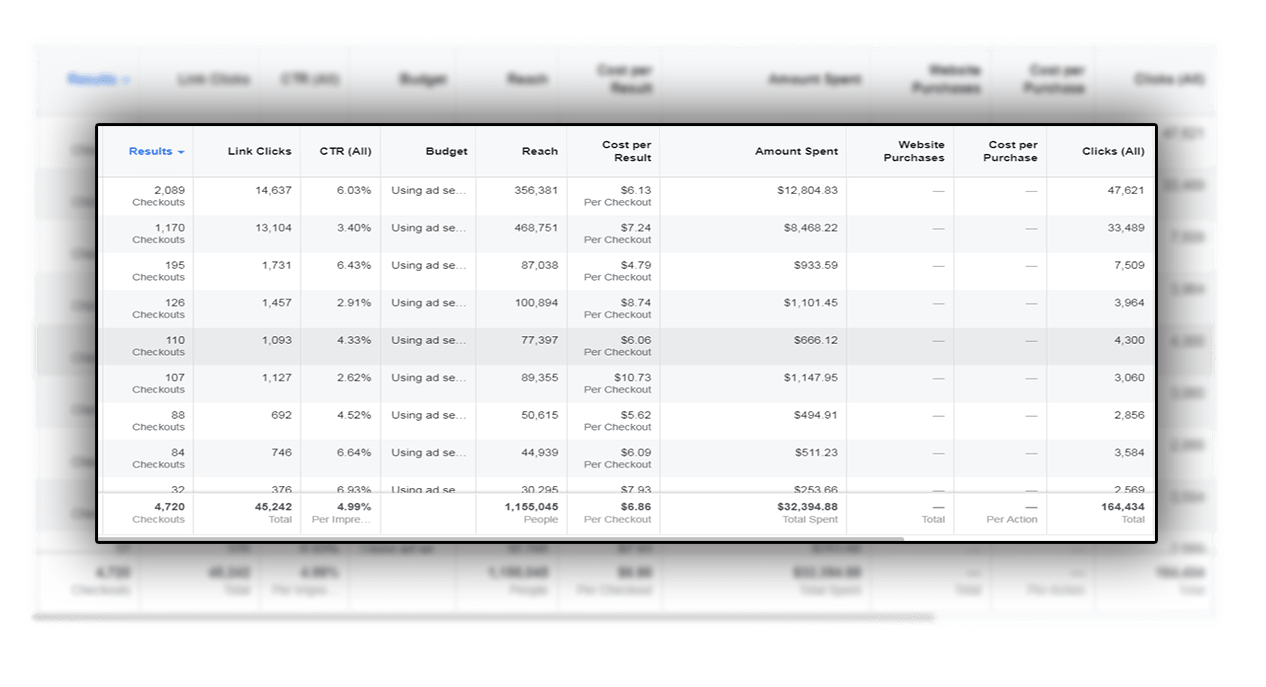
With Teespy, Even Newbies Can Create An Ultra-Profitable Facebook Ad Campaign
Look What Real People
HAVE TO SAY ABOUT TEESPY
We use a lot of tools in this industry, but this is one that I use every single day. It's got everything that a custom apparel marketer could possibly need, AND it's regularly updated to keep up with the industry. I've tried the competition and it simply doesn't hold up (bad support, broken features, etc...). Couldn't live without this baby.
Yousef Khalidi TassKickers #AK Nation

Teespy, for me is everything and more that I need to research new ideas. Not only can I see exactly what is selling and on what platform, but the live Facebook ads features is worth the money alone just to see exactly what engagement the campaigns are getting. I now do this full time and know I wouldn't have gotten this far without TeeSpy.
Kevin Reid Full-Time Entrepenuer

Teespy is the only way to do T-shirt research. Go ahead and do it the old way... waste a lot of time and find data that you really can't count on. This is the new way to do it. This is the right way to do it. anyone doing T-shirts should be using TeeSpy to spy!
Justin Cener Serial Entrepreneur

More Proof That Teespy Makes It Easy To Profit
WITHOUT ANY HARD WORK OR STRESS
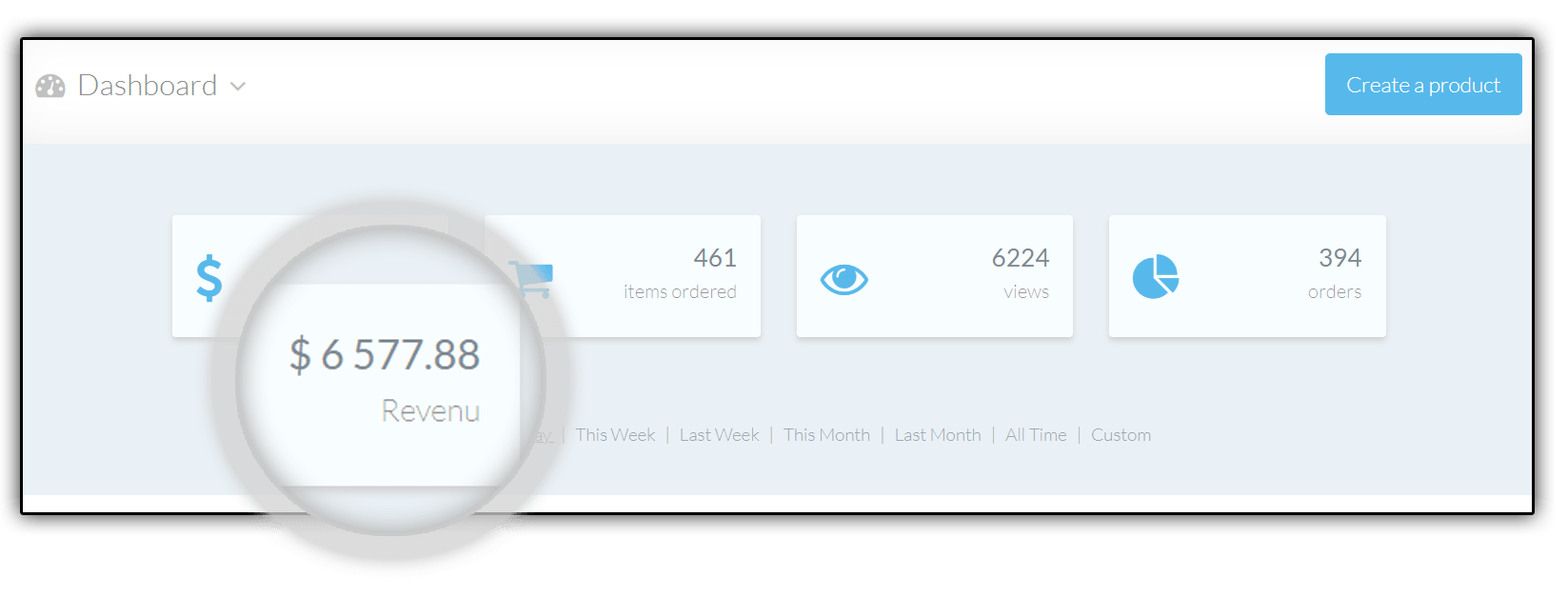
We’ve Slashed The Price On Teespy
WHEN YOU GET IT RIGHT NOW
Choose An Option Below Right Now To Lock-In Your Special Discount
Choose From 3 Affordable Plans
Starter
- Newest Campaigns
- Favorites
- Search
- Top Campaigns
- View Campaign Metrics
- Get General Details For Campaigns
- Get Trending Metrics:
- 8 Hour - NO
- 24 Hour - NO
- 3 Day - NO
- 7 Day - NO
- 15 Day - NO
- 30 Day - NO
- Get Up To 1 Alert
- 25 Notifications Per Day
- Marketing - NO
- Niches - NO
- Trends - NO
- Inspiration - NO
Normally $47 Per Month
Now Just $27 Per Month

Pro
- Newest Campaigns
- Favorites
- Search
- Top Campaigns
- View Campaign Metrics
- Get General Details For Campaigns
- Get Trending Metrics:
- 8 Hour - NO
- 24 Hour - NO
- 3 Day - NO
- 7 Day - YES
- 15 Day - YES
- 30 Day - YES
- Get Up To 1 Alert
- 25 Notifications Per Day
- Marketing - NO
- Niches - NO
- Trends - NO
- Inspiration - NO
Normally $97 Per Month
Now Just $47 Per Month
Business
- Newest Campaigns
- Favorites
- Search
- Top Campaigns
- View Campaign Metrics
- Get General Details For Campaigns
- Get Trending Metrics:
- 8 Hour - YES
- 24 Hour - YES
- 3 Day - YES
- 7 Day - YES
- 15 Day - YES
- 30 Day - YES
- Get Up To 250 Alerts
- Unlimited Notifications Per Day
- Marketing - YES
- Niches - YES
- Trends - YES
- Inspiration - YES
Normally $197 Per Month
Now Just $97 Per Month
Why You Need To Jump
ON THIS AND GET TEESPY RIGHT NOW
- The price is going up soon and if you close this page and come back later to get Teespy, you’ll end up missing out on the special discount
- Teespy works fast - You can find amazing product ideas that people will love within just a few minutes from right now
- The sooner you get started with Teespy, the sooner you’ll start making money
You Have No Risk When You Get Teespy Today
WITH OUR 30-DAY MONEY BACK GUARANTEE
We get it… you might be a little skeptical at this point.
There are a lot of people making big promises out there but rarely do you run across an app that actually does exactly what it says.
Teespy is one of those apps that works just like we say, and when you use this point-and-click app…
...you’ll finally have everything you need to make your next T-shirt campaign a huge success.
- No more stressing over coming up with ideas…
- No more wondering if your campaign will take off…
- No more trying to figure out how to get results with Facebook ads…
- With Teespy, it’s easier than ever to make big profits on your next T-shirt campaign...
And we’re so sure that Teespy will work for you that we’re going to make this easy by giving you 30 days to make sure this is for you.
You have NO RISK when you get Teespy right now.

Why You Need To Jump On This
AND GET TEESPY RIGHT NOW
The Discounted Price Is About To Go Away Forever
The price is going up soon and if you close this page and come back later to get Teespy, you’ll end up missing out on the special discount
You Only Get The FREE Bonuses When You Get This Now
The special bonuses we’ve included are only available when you get Teespy now. If you close the page and come back later, you risk missing out on these bonuses that will help you get even better results with Teespy.
You Get 30 Days To Make Sure This Is For You
Test-drive Teespy for 30 days to really make sure this is what you need. We know you’ll be blown away by just how easy this tool makes it to make big money on your t-shirt campaigns, but if you change your mind for ANY reason, all you have to do is let us know and we’ll get you a refund.
You Can Launch A Wildly Profitable Campaign TODAY
The sooner you get going, the sooner you’ll make money. Get Teespy right now, spy on some winning campaigns and ads, and create a campaign that puts money in your pocket TODAY!
Are You Ready To Get Results Like This
ON YOUR NEXT T-SHIRT CAMPAIGN?
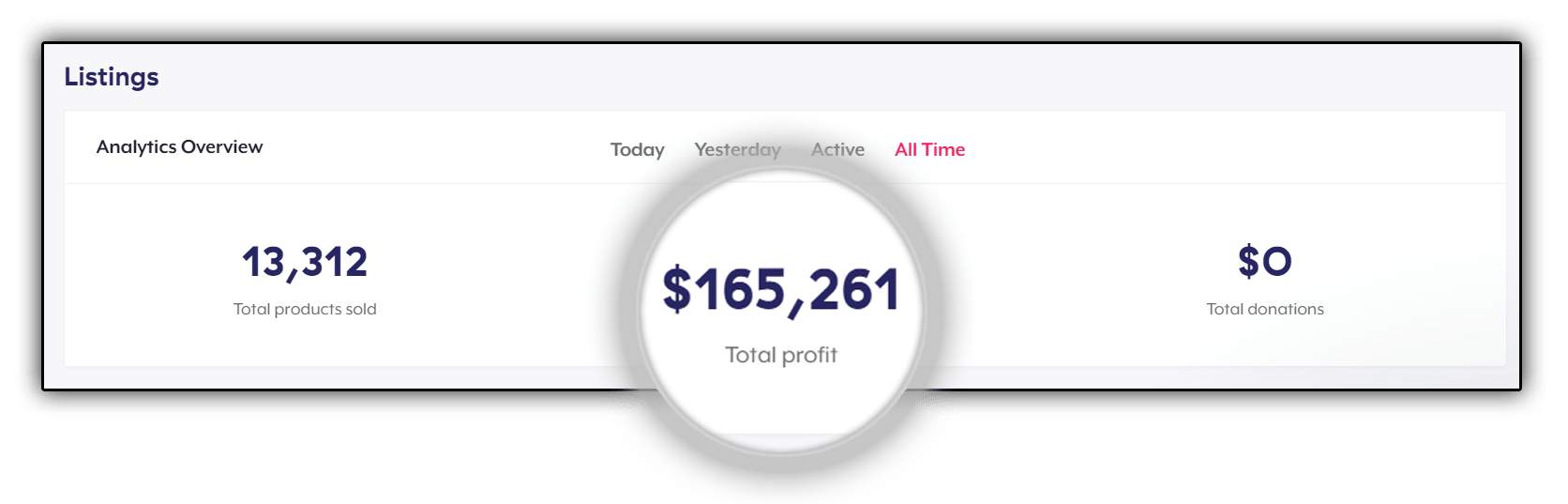
If You Answer ‘Yes’ To Any Of The Following,
YOU NEED TO GET TEESPY RIGHT NOW

- You’re new to running t-shirt campaigns and you want your first campaign to be a big success
- You can’t seem to come up with an idea for a solid t-shirt and you need some inspiration
- You’ve tried to run Facebook ads in the past and you struggled to get profitable
- You’ve had more campaigns bomb than you want
- You like the idea of making easy money and taking a huge shortcut to success
Let’s Recap Everything You Get When
You Get Teespy Right Now
- Instant Access To Teespy - Real World Value = $297
- Step-By-Step ‘Fast Start’ Teespy Training - Real World Value = $397
- Support And Updates - Real World Value = $297
Total Value Of Everything You Get Today Is
$991
Frequently Asked Questions About Teespy
What is Teespy
Teespy is an easy-to-use, cloud-based app that lets you spy on winning t-shirt campaigns and the exact Facebook ads being used so you can save time, avoid frustration, and make big money on your next campaign.
Who needs to get Teespy?
If You Answer ‘Yes’ To Any Of The Following, You Need To Get Teespy Right Now
- You’re new to running t-shirt campaigns and you want your first campaign to be a big success
- You can’t seem to come up with an idea for a solid t-shirt and you need some inspiration
- You’ve tried to run Facebook ads in the past and you struggled to get profitable
- You’ve had more campaigns bomb than you want
- You like the idea of making easy money and taking a huge shortcut to success
Do I have to install or update this software?
With Teespy, there are just 3 steps to a highly-profitable campaign...
So this will work on my Mac or PC?
Yes, you can use Teespy from your Mac, your PC, and even your tablet or smartphone.
How exactly does Teespy work?
Yes, you can use Teespy from your Mac, your PC, and even your tablet or smartphone.
- Step #1 - Login to Teespy (It’s cloud-based so you can use it from any device with an internet connection)
- Step #2 - Enter a keyword to start spying
- Step #3 - Get access to all kinds of t-shirt ideas, spy on winning campaigns, and get access to real Facebook ad campaigns so your next t-shirt campaign will be a MASSIVE success!
What kind of results should I expect when I use Teespy?
- No more struggling to come up with ideas
- No more struggling to come up with ideas
- Save a ton of time and money by spying on winning ad campaigns
- Discover the secret formula for banking THOUSANDS of dollars on every single campaign
Are there any incentives for me to get Teespy right now?
Yes. We’ve discounted the price and we’re giving over $1,111 in bonuses for FREE when you get Teespy right now.
Is there a money back guarantee when I get Teespy right now?
Yes, you get a full 30 days to make sure this is for you. If you change your mind for any reason, just let us know and we’ll get you a refund.
How do I take advantage of the discounted pricing on Teespy?
Choose One Of The Discounted Options
Below Right Now For Instant Access
Choose From 3 Affordable Plans
Starter
- Newest Campaigns
- Favorites
- Search
- Top Campaigns
- View Campaign Metrics
- Get General Details For Campaigns
- Get Trending Metrics:
- 8 Hour - NO
- 24 Hour - NO
- 3 Day - NO
- 7 Day - NO
- 15 Day - NO
- 30 Day - NO
- Get Up To 1 Alert
- 25 Notifications Per Day
- Marketing - NO
- Niches - NO
- Trends - NO
- Inspiration - NO
Normally $47 Per Month
Now Just $27 Per Month
Pro
- Newest Campaigns
- Favorites
- Search
- Top Campaigns
- View Campaign Metrics
- Get General Details For Campaigns
- Get Trending Metrics:
- 8 Hour - NO
- 24 Hour - NO
- 3 Day - NO
- 7 Day - YES
- 15 Day - YES
- 30 Day - YES
- Get Up To 1 Alert
- 25 Notifications Per Day
- Marketing - NO
- Niches - NO
- Trends - NO
- Inspiration - NO
Normally $97 Per Month
Now Just $47 Per Month
Business
- Newest Campaigns
- Favorites
- Search
- Top Campaigns
- View Campaign Metrics
- Get General Details For Campaigns
- Get Trending Metrics:
- 8 Hour - YES
- 24 Hour - YES
- 3 Day - YES
- 7 Day - YES
- 15 Day - YES
- 30 Day - YES
- Get Up To 250 Alerts
- Unlimited Notifications Per Day
- Marketing - YES
- Niches - YES
- Trends - YES
- Inspiration - YES
Normally $197 Per Month
Now Just $97 Per Month
Don’t Wait! The price for Teespy goes up very soon. If you wait and come back later, you’ll end up paying a lot more to get this.